
Highlights: IBM’s Big Data for Smart Grid Goes Live In Texas
Welcome to the International Informix Users Group (IIUG) Insider! Designed for IIUG members and Informix user group leaders, this publication contains timely and relevant information for the IBM Informix community.
Contents:
- Editorial
- Highlights
- Conference corner
- Developer corner
- Informix news
- Support corner
- Informix corner
- Sponsor corner
- Informix resources
- Calendar of events
- Useful links
- Closing and credits
| Editorial | Back to top |
October looks like it was ages ago. Since the last Insider we had war, once again, in our region. I hope it is the last one but find it hard to believe.
The vNext EVP is on its way. Those who are participating are aware of the great improvements. The rest will need to wait until it is GA. I hope it will be announced at our conference. One more reason to come. Registration is now open.
Looking forward to meeting you all in San Diego.
Gary Ben-Israel
IIUG Insider Editor
| Highlights | Back to top |
IBM’s Big Data for Smart Grid Goes Live In Texas
Last week, IBM publicized a big data project with client Oncor, the largest electricity distribution and transmission company in Texas, that delivers an advanced smart grid to help 3 million households conserve energy.
Coverage focused on the benefits of the project with local media reporting from Fort Worth Star Telegram, and industry and tech publications including InformationWeek, Smart Grid News, Green Tech Media, Inside Big Data, Seeking Alpha, Data-Informed, Utility Products and TMC Net. An IBM bylined article in Dataversity exploring how big data is transforming the energy and utilities industry was timed to run with the news.
Highlights
Oncor Electric Delivery…says it is teaming up with IBM on a new data management project designed to give consumers a better look at their electricity usage. The online service works with advanced “smart” meters and other networked devices installed at homes and businesses to provide a nearly real-time monitor of consumption, the companies were set to announce today. The system also gives Oncor automatic alerts on power issues and outages. —Fort Worth Star Telegram
When IBM came on board, Oncor was expanding its project to more than 3 million advanced meters, each of which sends information every 15 minutes to Oncor’s offices — a dramatic increase over a traditional electric meter with its monthly readings. The logistics posed a classic big-data challenge. How could Oncor process and store all of that data in a cost-effective way? Oncor needed to upgrade from its relational database management system, which was efficient at managing modest volumes and velocities of data, but was too inefficient for the new smart grid. So Oncor installed IBM’s Informix database software to run its smart grid. The new Informix system loaded meter data 20 times faster, and performed queries up to 30 times faster than the system it replaced, IBM claims. In addition, it reduced data storage needs by 70%, an improvement that remained linear over time and therefore allowed Oncor to accurately predict its storage requirements. —InformationWeek
IBM is a giant in smart grid big data, with partners around the world using its IT heft to link up power meters, grid sensors, leak detectors for water networks, and other end devices into the back-end systems that make them run. —Seeking Alpha
IBM and big Dallas-area utility Oncor announced the latest achievement on this long-running relationship – a big data platform that’s analyzing Oncor’s 118,000-plus miles of power lines, crunching data from its 3 million or so, smart meters from Landis+Gyr and meter data management software from Ecologic Analytics (both owned by Toshiba), and rolling out the results for both utility operations staff and to customers via the state’s smart meter web portal. —GreenTech Media
In its big data initiative with Oncor, the largest electric delivery company in Texas, IBM points to a list of benefits… Oncor now has pinpoint access and insight into billions of data measurement points, from advanced meters and networking devices, to transmission sensors, power lines and generation plants. Many Texas households have noted a 10 percent decrease in energy usage since the implementation. — Smart Grid News
Media
Fort Worth Star Telegram – Near-instant electric use data planned
By: Jim Fuquay, November 5, 2012
InformationWeek – Big Data Meets Texas Smart Energy Grid
By Jeff Bertolucci, November 12, 2012
Inside Big Data – Smart Grids Meet Big Data: Oncor Joins Global Intelligent Utility Network Coalition
By: Staff, November 5, 2012
Seeking Alpha – IBM’s Big Data For Smart Grid Goes Live In Texas
By Jeff St. John, November 9, 2012
Smart Grid News – Data analytics buying guide part 1: What’s in Big Data for you?
By Staff, November 5, 2012
GreenTech Media – IBM’s Big Data for Smart Grid Goes Live in Texas
By Jeff St. John, November 8, 2012
Data-Informed – Texas Utility Oncor Launches Smart Grid Project with IBM
By Christopher Nerney, November 6, 2012
TMC Net – Oncor Knows Outage Detection
By Joe Wolf, November 6, 2012
Dataversity – IBM Partners with Oncor to Bring Smart Grid to Texas
By Angela Guess, November 6, 2012
TMCNet – Texas Goes Live with IBM’s Big Data for Smart Grid
By Tabitha Naylor, November 12, 2012
Utility Products – IBM Tackles Big Data to Deliver Advanced Power Grid
For more information about Oncor, please visit www.oncor.com or follow Oncor on Twitter and Facebook.
For more information about IBM big data technologies, please visit www.ibm.com. For more information about IBM Informix software, an important element of IBM’s big data technologies, please visit: www.ibm.com. You can also follow @IBMBigData on Twitter.
For more information about Smarter Energy at IBM, please visit: www.ibm.com. Follow IBM Smarter Energy on Twitter and LinkedIn.
| Conference corner | Back to top |
IIUG Informix Conference 2013 – Call for speakers
Please join us April 21 — 25 as we return to beautiful San Diego, CA and the Marriott Mission Valley.
The 2013 conference will continue to provide the quality you are familiar with but with one major addition: This year the conference tutorials have been moved to Thursday April 25th and are included with all paid registrations. The conference will begin Sunday evening with the Welcome Reception. There will be three full days of conference seminars with a variety of topics to choose from and we will also continue to offer our Hands-on sessions. Don’t forget the valuable networking opportunities as well as the exceptional sponsors offering products and services for your business. The conference will introduce several new speakers, offering new and relevant topics related to using IBM Informix to meet all of your business needs.
Register for the conference by the Early Bird date of January 17, 2013 and receive a $275 discount off the regular price of registration. IIUG members can save an additional $100. Don’t forget, this year the tutorials are included at no additional cost for all paid attendance making this conference an even better value.
Reinforce your professional skills and distinguish yourself in today’s competitive environment by becoming IBM Certified. IBM Informix certification testing will be available during this year’s conference at no cost to attendees for the first test. Additional tests can be taken for a nominal fee. Become certified in areas of Optimization, Tuning, Administration and 4GL programming. The entire IBM certification portfolio will be available, so test in one or more disciplines while attending the conference.
Still haven’t read enough to justify attending the 2013 IIUG Informix Conference? Check the Justification document and share it with your supervisor for a list of additional reasons to attend. The Conference, including seminar content, tutorials, certification testing, hands-on labs and the opportunity to speak with Informix-specific professionals, is definitely a bargain when considering where to invest your 2013 training dollars.
See you at the conference!
2013 IIUG Conference Planning Committee
Click here to learn more about the conference
Follow IIUG 2013 on Facebook and Twitter
| Developer corner | Back to top |
Save this link to find about Informix on DeveloperWorks: /url/devworks.html
| Informix news | Back to top |
IBM Data Management Magazine
The Preeminence of IBM Informix TimeSeries, Part 2
Handling the large volumes of time-stamped data generated from stock transactions, smart metering, and more
Ashdown Group
New Informix Database Administrator job in Scotland
Due to continued growth they are in urgent need of an experienced Informix Database Administrator to take an instrumental client facing position
Banking Business Review
Congo’s RAWBANK deploys IBM smarter computing technology
Offering technology architecture and flexibility, the new core banking systems such as IBM Blade Center HS22, PS700 servers and Informix …
Sacramento Bee
RAWBANK Adopts IBM Smarter Computing Solution to Drive Business Growth and Expansion
RAWBANK has also been using IBM’s Informix software for its database and information management.
IBM Informix Business Partner Montage
A montage taken by the IOD client reference team. Informix users talking about the value of Informix to their business.
Why NOT Informix
Replay of the Webcast hosted by Tom Reiger (IBM Informix) — We all talk about “data explosions”, “more users”, “uglier queries and questions’. Informix is here to help you do what is NEXT around all those needs – and do it with less. Less hardware. Less administration. Less total cost. Webcast was hosted by : TOM RIEGER (IBM Informix).
| Support corner | Back to top |
Communication Setting Optimizations: Fetch Buffer Size
This setting applies to Informix client-server communications when using the SQLI protocol. While it can be set for other types besides TCP (shared memory or pipe), as we will see, it is only really useful for TCP connections.
When the server responds to a client request for data, it arranges the data in an buffer of the size requested by the client. The data is arranged by tuples, or rows. When the buffer is full, or the server has come to the end of the rows being fetched, the buffer is copied over the communication channel to a like buffer within the client application process memory. The client API (ODBC, JDBC, ESQL…) reads from the buffer, and copies or transforms the data into application variables as the application requests rows. When the client comes to the end of the buffer, and there is still more data in the result set, the client requests the server to send it another buffer of data.
The fetch buffer size setting is intended to allow the application to reduce the number of times the client API has to request another buffer. This setting is very much in the domain of speed versus size tradeoffs. Since at least one buffer has to be sent, there is no advantage to setting the buffer size to be larger than the typical, expected result set. Also, each buffer is associated with one executing statement; so, if there are lots of statements being processed concurrently, the size of the buffer can have an impact on the application’s memory footprint.
A simple way of thinking of how the fetch buffer size affects the application performance is to think of it in terms of number of buffers per result set, times how long of an inherent delay there is between the client and server. If the result set size is small, or the communication channel has little to no delay (which is always the case with shared memory or pipe connections), there is no significant benefit to larger buffer sizes. What follows are the results of series of tests where the result set size, fetch buffer size, and network delay are varied.
These tests were written using the ODBC interface, but the pattern of results should be the same across all Informix APIs when using the SQLI protocol. The client and server are on the same physical machine, with the client running under Windows and the Informix server on a Linux virtual machine. The network delay is controlled using Linux’s network emulation (netem) functionality.
The data do not actually exist in the database; they are manufactured at the time of query execution through the use of views created to multiply the base result set. This configuration is not representative of any real world scenarios. So, while the pattern of effects produced from fetch buffer size settings is reliably produced, any other metrics, such as the number of queries per second, that might be inferred should not be considered to be representative of real world performance.
Empirical Results
The empirical results match predictions. As the size of the result set is increased, the effect of increasing the size of the fetch buffer is that slower communication between the client and the server has less effect. When sending large results to the client, it is possible to compensate for a slow network with a large fetch buffer. When the result size is small, or the network has little delay between the sending and receiving of packets, the setting of fetch buffer size has little effect.
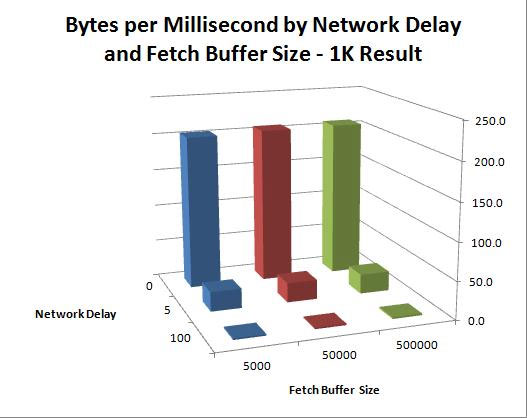
Example 1: Small result set size — 1K
Increasing the fetch buffer size beyond the size of the result set has no meaningful effect, across all network conditions.
Table 1. Result set 1K data
| Network Delay | |||
| 0 | 5 | 100 | |
| 5000 | 204.5 | 25.9 | 1.969887 |
| 50000 | 207.3 | 25.9 | 1.96818 |
| 500000 | 208.4 | 26.1 | 1.966548 |
Example 2. Moderate result set size — 256K
When there is a negligible network delay, the size of the fetch buffer has negligible effect. As the network delay increases, the effect of increasing the fetch buffer size becomes more significant. When the network delay is 100ms, increasing the fetch buffer can increase performance by over 6 times.
Table 2. Result set 256K data
| Network Delay | |||
| Fetch Buffer Size | 0 | 5 | 100 |
| 5000 | 576 | 355 | 38 |
| 50000 | 585 | 523 | 153 |
| 500000 | 580 | 551 | 262 |
Example 3. Large result set size — 4MB
When working with large result sets over a slow network, setting a large fetch buffer size can be crucial to performance. Notice that the data transfer rate of the largest buffer over the slowest network is only about 15% slower than the fastest condition, and 12 times faster than the same transfer using a small buffer.
Table 3. Result set 4MB data
| Network Delay | |||
| Fetch Buffer Size | 0 | 5 | 100 |
| 5000 | 583 | 372 | 41 |
| 50000 | 589 | 558 | 239 |
| 500000 | 595 | 583 | 504 |
The results above should provide a useful guide on an appropriate setting for fetch buffer size based on the actual queries being performed and the network infrastructure in use. The main drawback to a high setting of fetch buffer size is limited to when the memory footprint of the application starts to impede on memory requirements of other processes.
— Chris Golledge
| Informix corner | Back to top |
Informix University initiative update
UMKC has opened enrollment for a new course offering – Introduction to Health Informatics – and they will be using IBM Informix in the course. It will be taught by one of our long time faculty partner Prof. Praveen Rao as a “Special Topics” graduate level course. You can find the course description here.
New Informix book available in China
Lu Chuan, one of IBM Informix technical experts in China, has just published a new book about Informix 11.x. It is currently only available in Chinese but hopefully it will make it into other languages. Go here for a closer look or to order.
IBM Informix success story with customer Westfleisch e.G.
“High-volume meat production is a logistical challenge. This new solution provides us with critical business data from our nine meat-production locations much faster and more reliably than before.” — Joachim Badde, CIO, Westfleisch. Read more about this success store here.
| Where | When | Location | |
| Seattle | 4 Dec 2012 | Tap House | Details |
| Chicago | 6 Dec 2012 | IBM TEC | Details |
| North Texas | 11 Dec 2012 | Maximo Cocina | Details |
| Where | When | Location | |
| Informix Performance Tuning Bootcamp | 12-14 Dec 2012 | Shenzhen, China | Registration |
| Informix Genero Bootcamp | 4-7 Dec 2012 | Mexico City, Mexico | Registration |
| Sponsor corner | Back to top |
Advanced Informix Performance Tuning Course
December 3-6 2012 by Lester Knutsen and Art Kagel (attend online or in our classroom)
This course is confirmed and only has 3 spaces left.
Do you want to learn how to be the FASTEST Informix DBA? This is the course our Fastest Informix DBA contest was developed from, and it will increase your database performance tuning skills.
This 4-day course focuses on techniques for optimizing an Informix Database. Labs will demonstrate more than 100% performance improvement. Each student will have a 4-core Linux server with Informix 11 and a large dataset for benchmark exercises and labs. Attend the class in person or online via our Web Training Center. Both Art Kagel and Lester Knutsen will be teaching the Advanced Classes together.
The Advanced Informix Performance Tuning This course is for database administrators and application developers who will be responsible for managing, optimizing, and tuning an Informix database server. The focus is on skills, procedures, and scripts to improve the performance of your database server. The course will provide a toolkit of scripts and utilities to start monitoring and optimizing your Informix database server.
The course may be taken online on the web from your desk or at our training center in Virginia. All you need is a web browser and a SSH client (like Putty) to connect to the lab machines in our office.
Register online or call 703-256-0267 ext 101 for more information or to register by phone.
Visit our Informix Courses Schedules and Outlines page.
| Informix resources | Back to top |
http://www.informix.com or directly at: http://www-01.ibm.com/software/data/informix/
Blogs and Wikis that have been updated during the last month
- Planet IDS – Blogs, Videos, News and more *** Up to date feeds from many blogs ***
- Informix Support
- Roger Powell
- Informix Documentation Team
- IDS Experts
- Gary Proctor
- ognjen.orel
- Keshava Murthy
- Andrew Ford
- Mark Jamison
- Fernando Nunes
- Informix Interoperability with Other Products
More Blogs and Wikis
- Jerry Keesee
- John Miller
- A Latin blog maintained by support
- Eric Vercelletto (English)
- Eric Vercelletto (French)
- Louis T. Cherian
- Art Kagel’s
- Jacques Roy
Forums, Groups, Videos, and Magazines
- The IIUG forums
- Informix Marketing channel on YouTube
- IBM Data Management Magazine
- The Informix Zone
- There is now an Informix group on LinkedIn. The group is called “Informix Supporter”, so anyone loving Informix can join, from current IBM employees, former Informix employees, to users. It will also be a good occasion to get in touch with others or long-time-no-seen friends. If you fancy showing the Informix logo on your profile, join. Join here
| Calendar of events | Back to top |
| December – 2012 | |||
| Date | Event | Location | Contact |
| 4 | Seattle Informix User Group Meeting | Seattle, Washington | |
| 6 | Chicago Informix User Group Meeting | IBM TEC Center, Chicago Illinois | rbeal@us.ibm.com |
| 11 | North Texas Informix User Group Meeting | Dallas, Texas | |
| Useful links | Back to top |
| Closing and credits | Back to top |
The International Informix Users Group (IIUG) is an organization designed to enhance communications between its worldwide user community and IBM. The IIUG’s membership database now exceeds 25,000 entries and enjoys the support and commitment of IBM’s Data Management division. Key programs include local user groups and special interest groups, which we promote and assist from launch through growth.
| Sources: | IIUG Board of Directors IBM Corp. |
|
| Editors: | Gary Ben-Israel Rhonda Hackenburg |
For comments, please send an email to gary@iiug.org.